Why Web Servers Aren't Built for 4-Hour AI Jobs
Web servers are designed for millisecond-to-second responses — holding a connection open for minutes or hours causes timeouts, memory growth, and zero crash recovery if the server restarts.
See also: background jobs on Vercel with cron.
I built an AI report generation SaaS with three products at very different runtimes: Life Clarity at ~15–20 seconds, Personal Blueprint at ~110–136 seconds, and Personal Horoscope at 141–190 minutes in production. No HTTP framework can hold a connection open for four hours. Run AI generation synchronously inside a FastAPI route and you get a 502 after 30–60 seconds on Render, Railway, or Vercel — the customer paid, the job never started, MongoDB stays at pending forever.
The naive fix — asyncio.create_task() or FastAPI BackgroundTasks — keeps work in the same process as the web server. Deploy a new version, hit OOM during PDF assembly, or restart the container: the in-flight job vanishes. No Redis message. No retry. For a twenty-second job that might survive; for 161 GPT-4o calls over four hours it is a refund waiting to happen.
The three runtimes in the platform
Three timeout killers stack on naive synchronous code:
- Web server request timeout: 30–60 seconds on most hosts — the API process is killed mid-generation.
- Browser HTTP timeout: connections drop after two or more minutes of no response — the client sees a spinner forever.
- Celery global default: soft 600s, hard 660s — kills a 141-minute job at the ten-minute mark if you forget per-task overrides.
| Approach | Max safe duration | Crash recovery | Progress visibility | Output delivery |
|---|---|---|---|---|
| Synchronous request | 30–60s (server timeout) | ❌ Lost on crash | ❌ None | HTTP response |
| FastAPI BackgroundTasks | ~30s (in-process, lost on restart) | ❌ Lost on restart | ❌ None | HTTP response or callback |
| Celery fire-and-forget | Hours (with per-task limits) | ✅ task_acks_late | Polling / SSE | Email + PDF link |
| WebSocket | Limited by connection | ❌ Connection drops | ✅ Real-time | Streaming bytes |
| Best for 4-hour AI jobs | — | Celery ✅ | Celery ✅ | Email ✅ |
The problem is not that AI generation is slow — it is that the code is structured to make the HTTP connection wait for it. These are different concerns and need to live in different processes. Accepting a payment and generating 161 GPT-4o calls are two jobs. A web server doing both is the wrong tool for the second one.
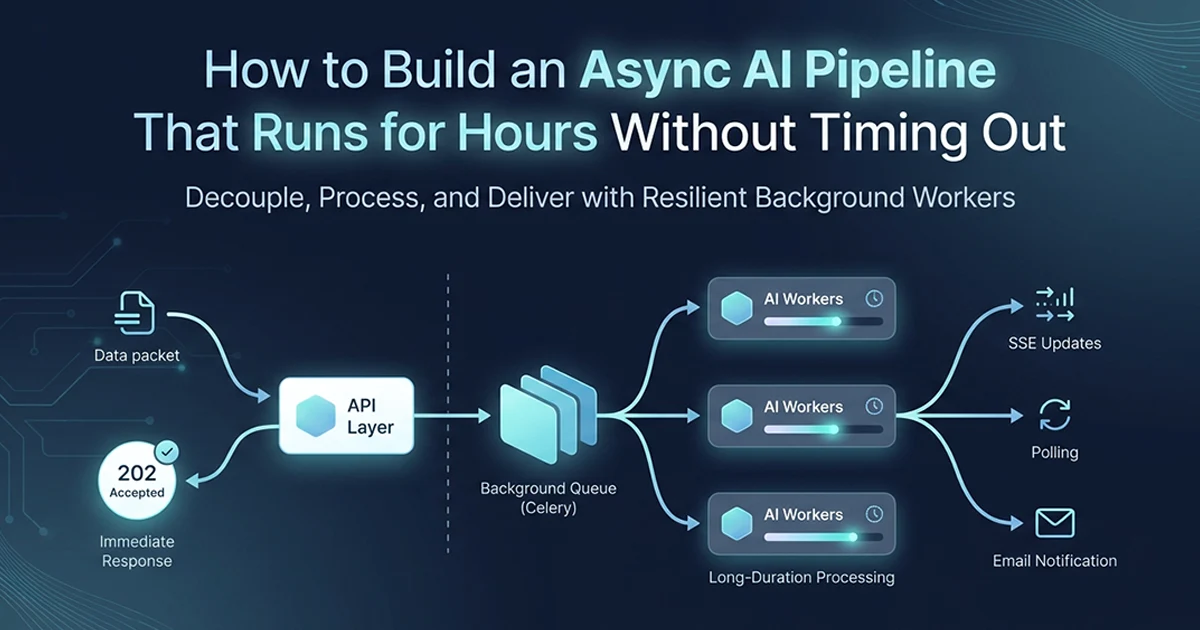
The Fire-and-Forget Architecture: Two Paths, Two Processes
Separate the request path (accept and return immediately) from the worker path (complete the work independently) — they share only a job ID and a shared database for state. This is the core async AI pipeline Python long running without timeout pattern.
Request path (milliseconds to seconds)
- Customer →
POST /api/v1/payments/checkout→ create Stripe session → insert MongoDB record (status=pending) → return HTTP 202 Accepted + checkout URL. - Customer completes Stripe payment.
- Stripe →
POST /api/v1/payments/webhook→ verify signature → idempotency check → update MongoDBstatus=generating→ dispatch Celery task → return HTTP 200 immediately.
The API process is done after step 3. It never waits for the AI job.
Worker path (independent process, seconds to hours)
- Celery worker picks up task from Redis queue.
- Pre-computation runs (domain calculations, not AI).
- AI generation runs (4 to 161 GPT-4o calls).
- PDF assembled (1 to 173 WeasyPrint chunks).
- PDF uploaded to Vercel Blob.
- MongoDB updated:
status=ready,pdf_urlstored. - Delivery email sent via SendGrid. Customer receives email. Job complete.
The request path and worker path communicate only through MongoDB (shared state) and Redis (queue). Neither waits for the other. The webhook handler returns HTTP 200 in milliseconds — Stripe's retry window never opens. The checkout endpoint returns HTTP 202 — the frontend redirects to Stripe and polls status later. Two HTTP responses, zero blocking on AI generation.
After AI generation completes inside the worker, the pipeline assembles PDF (1 to 173 WeasyPrint chunks depending on product), uploads to Vercel Blob with a 60-second timeout, sets pdf_url in MongoDB, updates report_status to ready, and sends the delivery email. The worker updates MongoDB after email sent — not after AI generation alone — so a customer never sees ready status without a deliverable PDF.
# app/api/routes/payments.py
from fastapi import APIRouter, status
from fastapi.responses import JSONResponse
from app.schemas.payment import CheckoutRequest
from app.services import payment_service
from app.repositories.payment_repo import payment_repo
router = APIRouter()
@router.post("/checkout", status_code=status.HTTP_202_ACCEPTED)
async def create_checkout(request: CheckoutRequest) -> dict:
session = await payment_service.create_checkout_session(request)
# Pre-create job record — status=pending before payment completes
await payment_repo.create_pending_record(session.id, request)
# HTTP 202: "I've accepted your request. Processing happens asynchronously."
# NOT 200 — 200 means done. 202 means poll for status or wait for email.
return JSONResponse(
status_code=status.HTTP_202_ACCEPTED,
content={
"session_id": session.id,
"checkout_url": session.url,
"status": "pending",
},
)
Why 202 Accepted, not 200 OK
HTTP semantics matter. 200 OK means the request completed — here is the result. 201 Created means a resource was created at a location. 202 Accepted means the request was received and processing will happen asynchronously. The checkout URL redirects to Stripe's hosted page — another async step. Returning 202 signals to clients: do not wait for a result on this connection — poll /status/{session_id} or wait for email. Mixing 200 on checkout would mislead frontend code into expecting a completed report in the response body.
The API's job is to accept work. The worker's job is to complete it. These are different jobs and they need different processes. A web server that holds a connection open for four hours is not a web server — it is a worker that happens to speak HTTP.
Per-Task Time Limits: Configuring Celery for Jobs That Run Hours, Not Minutes
Celery's global time limit defaults will kill long-running AI jobs — override them per task, and always set a soft limit that fires before the hard kill to give your task time to persist state before termination.
The global default problem
Global defaults: soft 600s (10 min), hard 660s (11 min). Fine for Life Clarity running in under 30 seconds. Fatal for a 141–190 minute Horoscope job. Without override: SoftTimeLimitExceeded at ten minutes, hard SIGKILL at eleven. MongoDB stays at status=generating forever. Customer gets nothing. No email. No refund trigger.
The architecture decision: set global defaults conservatively for short tasks, override per product in the task decorator. Life Clarity uses global defaults. Blueprint gets soft 480s / hard 540s. Horoscope gets soft 21,600s / hard 22,500s. Bundle coordinator gets soft 120s / hard 180s because it only dispatches three sub-tasks and exits — it never runs AI generation itself.
Per-task soft and hard limit overrides
# app/workers/tasks.py
import structlog
from celery.exceptions import SoftTimeLimitExceeded
from app.workers.celery_app import celery_app
logger = structlog.get_logger()
# Short job — global defaults fine (600s soft / 660s hard)
@celery_app.task(
name="app.workers.tasks.generate_report",
bind=True,
max_retries=2,
acks_late=True,
reject_on_worker_lost=True,
queue="queue.life_clarity",
)
def generate_report(self, session_id: str, metadata: dict) -> None:
try:
run_fast_pipeline(session_id, metadata)
except SoftTimeLimitExceeded:
logger.error("fast_report_timed_out", session_id=session_id)
update_status(session_id, "failed")
# Long job — 6-hour soft, 6.25-hour hard kill
@celery_app.task(
name="app.workers.tasks.generate_long_report",
bind=True,
max_retries=2,
acks_late=True,
reject_on_worker_lost=True,
soft_time_limit=21_600, # 6 hours — fires SoftTimeLimitExceeded
time_limit=22_500, # 6.25 hours — SIGKILL (no cleanup)
default_retry_delay=60,
queue="queue.personal_horoscope",
)
def generate_long_report(self, session_id: str, metadata: dict) -> None:
try:
run_long_pipeline(session_id, metadata)
except SoftTimeLimitExceeded:
# 900s gap (22,500 - 21,600) = 15 min to persist state before SIGKILL
logger.error("long_report_soft_limit", session_id=session_id)
update_status(session_id, "failed")
raise
except Exception as exc:
raise self.retry(exc=exc, countdown=60 * (2 ** self.request.retries))
The 15-minute gap between soft and hard kill
The 900-second gap between Horoscope soft (21,600s) and hard (22,500s) limits gives the task fifteen minutes to persist its current state. If the task was at batch 140 of 161 when the soft limit fired, those 140 batches are already checkpointed in MongoDB. The task can update status to failed and exit cleanly before SIGKILL arrives. Blueprint overrides: soft 480s, hard 540s. Bundle coordinator: soft 120s, hard 180s — it only dispatches sub-tasks. Life Clarity never needs overrides — it finishes in under thirty seconds on global defaults.
Set the soft-to-hard gap to at least fifteen minutes for very long tasks. The soft limit is your warning shot — it gives the task time to save progress. The hard SIGKILL is the last resort. A 60-second gap is too narrow for anything that needs to write to a database before termination.
How Clients Know When the Job Is Done: Polling, SSE, and Email
Three mechanisms handle different job durations: polling for short and medium jobs, SSE for real-time bundle progress, and email for very long jobs where the client waits for delivery regardless of browser state.
The MongoDB state machine
Status lifecycle: pending → generating → ready | failed | expired.
pending→generating: webhook handler after payment confirmed.generating→ready: Celery worker after delivery email sent.generating→failed: worker after max_retries exhausted.pending→expired: webhook oncheckout.session.expired.
The polling endpoint pattern
# app/api/routes/status.py
import asyncio
import json
from fastapi import APIRouter, HTTPException, Request
from fastapi.responses import StreamingResponse
from app.repositories.payment_repo import payment_repo
router = APIRouter()
@router.get("/status/{session_id}")
async def get_status(session_id: str) -> dict:
payment = await payment_repo.find_by_session_id(session_id)
if not payment:
raise HTTPException(status_code=404, detail="Order not found")
return {
"status": payment["report_status"],
"pdf_url": payment.get("pdf_url"),
"report_type": payment.get("report_type"),
}
@router.get("/status/{session_id}/stream")
async def stream_status(session_id: str, request: Request):
"""Server-sent events for real-time bundle status updates."""
async def event_generator():
while True:
if await request.is_disconnected():
break
payment = await payment_repo.find_by_session_id(session_id)
data = {
"report_status": payment["report_status"],
"lc_status": payment.get("lc_status"),
"bp_status": payment.get("bp_status"),
"ph_status": payment.get("ph_status"),
}
yield f"data: {json.dumps(data)}\n\n"
if payment["report_status"] in ("ready", "failed"):
break
await asyncio.sleep(5)
return StreamingResponse(
event_generator(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"X-Accel-Buffering": "no", # disable Nginx buffering for SSE
},
)
When to use polling vs SSE vs email
Polling: jobs under ten minutes where the user actively watches a page — client polls every 10–30 seconds. SSE: bundle orders with three concurrent sub-reports — frontend EventSource connects to the stream URL, receives lc_status, bp_status, ph_status updates every five seconds until all three reach ready. Email: jobs over ten minutes — email is the right delivery mechanism for async results that outlast a browser session.
Honest limitation: no granular progress within individual jobs (batch 80/161). SSE exists only for bundle status. A granular progress system would require worker → Redis → SSE endpoint → EventSource — added complexity not yet built. Customers running four-hour Horoscope jobs rely on the confirmation email at payment time and the delivery email at completion.
SSE connections from FastAPI need the X-Accel-Buffering: no header if you are behind Nginx or a reverse proxy. Without it, Nginx buffers the response until the connection closes — the client sees nothing until the job completes, defeating the purpose of streaming.
Email as the Delivery Mechanism for Long-Running AI Output
For AI jobs that take hours, email is the right delivery mechanism — it requires no open connection, works even if the user closes their browser, and delivers the result whenever it is ready regardless of timing.
Why not WebSockets or HTTP streaming for long jobs
WebSocket holds a connection — customer closes browser, loses connection. HTTP streaming holds the response — times out at the proxy layer after minutes. Email: fire and forget from the worker. Customer receives it when ready. For a four-hour job, email is not a fallback — it is the correct choice. Short jobs (~20s Life Clarity, ~3min Blueprint) send delivery email immediately after generation. Long Horoscope jobs: customer already received confirmation email at webhook time; delivery email arrives when the worker finishes.
The delivery email pattern
The worker sends email after: PDF bytes are in memory, MongoDB status updated to ready, and SendGrid accepts the message. The ~14 MB large report attaches directly as base64 (within SendGrid's 30 MB limit) plus a Vercel Blob download link as backup. No long-lived HTTP connection needed between customer and the AI job — they close the tab, go to sleep, and wake up to the PDF in their inbox.
This means no WebSocket, no HTTP streaming, no long polling for four-hour jobs. Email is the perfect async delivery mechanism for AI output with unknown completion time. The worker path owns delivery; the request path never touches the PDF bytes. Hassan Raza documents the Stripe webhook and Celery dispatch that starts this pipeline on hassanr.com — this post covers what happens after the webhook returns HTTP 200 and the connection closes.
MongoDB as the State Store: Persistence Across Worker Restarts
MongoDB is the single source of truth for job state — when a worker crashes mid-job, the next worker picks up the task from Redis and resumes from the last checkpointed section by reading MongoDB, not restarting from zero.
What would happen without persistent state
Worker crashes at batch 140 of 161. task_acks_late=True → task re-queues. New worker picks it up. Without MongoDB state: starts from batch 1, pays for 140 extra API calls (~$15–25). With MongoDB checkpointing: reads completed batches, starts from batch 141 (~$3–5 retry cost). The fire-and-forget architecture only works if the worker can resume — MongoDB checkpointing is what makes four-hour jobs survivable, not just dispatchable.
The checkpoint upsert pattern
After each AI generation step completes, upsert the result into MongoDB: await repo.upsert_section(session_id, section_id, result). On task restart: load completed sections, skip them, resume from first missing. Redis has per-task result TTL of 3,600 seconds — too short for a four-hour job that might restart partway through. MongoDB documents persist until explicitly deleted. This is why MongoDB, not just Redis, is the state store — Redis queues work; MongoDB remembers progress. Hassan Raza covers section-level checkpointing in detail alongside Celery reliability settings in the FastAPI + Celery production guide on hassanr.com.
Frequently Asked Questions
Use Celery and Redis for tasks over 30 seconds, return HTTP 202, and deliver by email for long jobs. Hassan Raza built an async AI pipeline Python long running without timeout pattern on an AI report SaaS with 141–190 minute runtimes. FastAPI accepts the request and dispatches to Celery immediately. Store job state in MongoDB — pending, generating, ready, failed. Override Celery's global 600s soft limit with per-task limits like soft_time_limit=21,600 for six-hour jobs. Deliver results by email when jobs exceed 10 minutes — no connection held open.
Separate request acceptance from task completion into two different processes. The FastAPI request path validates input, inserts a pending MongoDB record, dispatches a Celery task, and returns HTTP 202 Accepted with a session ID. The Celery worker path picks up the task from Redis, processes independently, updates MongoDB on completion, and sends email. The two processes share only MongoDB for state and Redis for queuing. HTTP 202 means accepted but not complete — clients poll for status instead of waiting on the connection.
Use polling for short jobs, SSE for bundle progress, and email for jobs over 10 minutes. GET /status/{session_id} returns report_status and pdf_url from MongoDB — clients poll every 5–10 seconds. SSE at /status/{session_id}/stream yields events every 5 seconds via EventSource — ideal for bundle orders with lc_status, bp_status, ph_status fields updating independently. Email delivers results for four-hour jobs with no open connection. MongoDB is the state store for all three. Set X-Accel-Buffering: no behind Nginx for SSE to work.