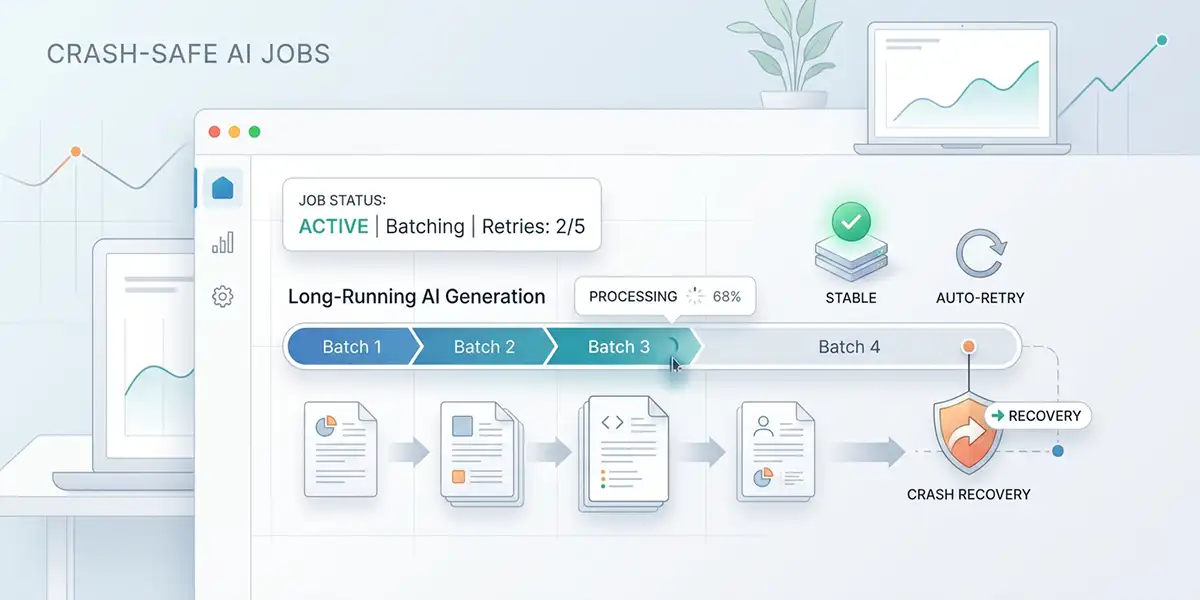
The Problem with Long AI Jobs
Most AI tutorials show you how to call GPT-4 once and render the response. Real production systems need to orchestrate hundreds of sequential API calls that can take hours to complete. When you're generating 8,600 personalized answers across 161 batch calls to GPT-4o, everything that can go wrong will go wrong:
See also: async AI pipelines for multi-hour jobs and Celery task queue configuration for AI jobs.
- Worker crashes halfway through (memory pressure, container restarts)
- OpenAI rate limits (429 errors even with exponential backoff)
- Network timeouts on individual API calls
- Deploys that kill in-flight tasks
- Database connection drops during batch writes
The naive approach — retry the entire job from scratch — burns API budget and doubles generation time. Users who paid $59.99 for a report shouldn't wait 8 hours because batch 147 of 161 failed. You need granular crash recovery that resumes exactly where it left off.
This article walks through five production patterns I use in Pulse Clarity, a multi-product SaaS that generates AI-powered PDF reports. The largest product makes 161 sequential GPT-4o calls, processes 8,600 answers, and assembles a 1,720-page PDF — all triggered by a single Stripe webhook and delivered by email 2–4 hours later.
The Architecture
Before diving into patterns, here's the stack that makes long-running jobs viable:
- FastAPI — thin REST layer, routes delegate to services immediately
- Celery with Redis — background task queue; one named queue per product (isolation between 20-second and 4-hour jobs)
- MongoDB — document store for payments, reports, and per-batch progress tracking
- OpenAI GPT-4o — all content generation; no RAG, all context is pre-computed
- WeasyPrint + pypdf — HTML → PDF chunks, then merge (one 1,720-page render would OOM)
- Render — 1 API service + 4 worker services (clarity, blueprint, horoscope, bundle), product-specific timeouts
The key insight: Celery tasks are not atomic transactions. A task can run for 4 hours, survive worker restarts, and resume mid-batch — if you design for it. Most Celery guides don't cover this because most tasks finish in seconds.
Pattern 1: Crash-Safe Batch Persistence
The foundation of reliable long jobs is persisting progress after every expensive operation. For the horoscope product (161 batches, ~2–4 hours), I persist to MongoDB after each GPT-4o call completes.
The Upsert Pattern
Every batch has a unique identifier (e.g. daily_2026_05_20, weekly_2026_w21). After generating content, I call upsert_batch():
# MongoDB update with $pull + $push for idempotency
def upsert_batch(self, session_id: str, batch_id: str, content: dict):
self.collection.update_one(
{"stripe_session_id": session_id},
{
"$pull": {"batches": {"batch_id": batch_id}}, # Remove old if exists
"$push": {"batches": {"batch_id": batch_id, "content": content}}
},
upsert=True
)The $pull then $push pattern ensures idempotency: if the worker crashes and Celery retries, re-upserting the same batch_id replaces the old data, not duplicate it. MongoDB's atomic update guarantees no partial writes.
Resume Logic
At the start of every task, I check what's already done:
completed_ids = repo.get_completed_batch_ids(session_id)
pending_batches = [b for b in manifest if b.batch_id not in completed_ids]
logger.info(
"resume_check",
total=len(manifest),
completed=len(completed_ids),
pending=len(pending_batches)
)
for batch_spec in pending_batches:
content = await generate_batch(batch_spec) # GPT-4o call
repo.upsert_batch(session_id, batch_spec.batch_id, content)
logger.info("batch_persisted", batch_id=batch_spec.batch_id)If the worker dies at batch 89 of 161, the next retry skips the first 88 and resumes at 89. No wasted API calls, no double-billing risk.
Store the full batch manifest (161 BatchSpec objects) in a constant at service start. Don't rebuild it dynamically mid-task — you need deterministic batch_ids for resume logic to work.
Pattern 2: Idempotent Task Design
Celery retries tasks on worker crashes (task_acks_late=True, reject_on_worker_lost=True). If your task isn't idempotent, retries create duplicates — duplicate emails, duplicate Stripe charges, duplicate database rows.
Guard Clauses at Task Entry
Every Celery task starts with a status check:
@celery_app.task(name="generate_horoscope")
def generate_horoscope_task(session_id: str):
report = repo.find_by_session_id(session_id)
if report and report.status == ReportStatus.READY:
logger.info("task_skip_already_complete", session_id=session_id)
return {"status": "already_complete"}
# Proceed with generation...
run_generation_pipeline(session_id)If the task is retried after completion (rare but possible), the guard returns early. No second email, no second PDF generation.
Webhook Deduplication
Stripe can send the same checkout.session.completed webhook multiple times (network retries, infrastructure blips). The payment service checks status before dispatching:
def handle_checkout_completed(session_id: str, product_type: str):
report = repo.find_by_session_id(session_id)
if report and report.status != ReportStatus.PENDING:
logger.warn("webhook_ignored_not_pending", status=report.status)
return # Already dispatched or completed
# Create report record with PENDING status
repo.create_report(session_id, product_type, status=ReportStatus.PENDING)
# Dispatch to product-specific queue
if product_type == "horoscope":
generate_horoscope_task.apply_async(args=[session_id])
# ...The check status != PENDING prevents duplicate dispatches. Combined with Celery's task guard, the pipeline is safe against webhook replays and task retries.
Pattern 3: Intelligent Batching
The horoscope product generates 365 daily forecasts + 52 weekly + 12 monthly + 1 yearly summary. Calling GPT-4o once per day (365 calls) would take too long and hit rate limits. Calling once for all 365 days produces generic, repetitive content.
The solution: time-period batch specs that balance output quality with API efficiency.
Batch Manifest Design
I pre-compute a manifest of 161 BatchSpec objects at service start:
@dataclass
class BatchSpec:
batch_id: str # "daily_2026_05_20"
batch_type: str # "daily" | "weekly" | "monthly" | "yearly"
periods: list[dict] # [{date: "2026-05-20", moon_sign: "Libra", ...}, ...]
token_budget: int # 4000 for daily, 6000 for weekly, etc.
def build_batch_manifest(start_date: date) -> list[BatchSpec]:
specs = []
# Daily: 3 days per batch (122 batches for 365 days)
for chunk in chunk_dates(start_date, days=365, chunk_size=3):
specs.append(BatchSpec(
batch_id=f"daily_{chunk[0].isoformat()}",
batch_type="daily",
periods=[get_transit_data(d) for d in chunk],
token_budget=4000
))
# Weekly: 2 weeks per batch (26 batches for 52 weeks)
# Monthly: 1 month per batch (12 batches)
# Yearly: 1 batch
# ...
return specs # Total: 161 batchesEach batch generates content for multiple periods in one GPT-4o call. The model receives context like:
Generate 20 Q&A answers for each of these 3 days: May 20 (Moon in Libra, Venus trine Jupiter), May 21 (Moon in Scorpio), May 22 (Moon in Scorpio, Sun square Mars). Return JSON with 60 total answers.
This reduces 365 calls to 122 daily batches while preserving per-day uniqueness through injected transit data.
I initially tried 7 days per batch. GPT-4o output quality degraded — answers became shorter and more generic past day 4. Reducing to 3 days per batch restored quality at the cost of 40 more API calls (acceptable trade-off for $59.99 product).
Pattern 4: Cost Control & Rate Limiting
A 161-batch pipeline calling GPT-4o with 4,000–8,000 token budgets can cost $8–$15 per report in API fees (rough estimate, varies with prompt length). At $59.99 retail, margins depend on controlling costs and avoiding rate-limit traps.
Per-Batch Token Budgets
Every BatchSpec has a token_budget tied to max_tokens in the API call:
TOKEN_BUDGET_DAILY = 4000
TOKEN_BUDGET_WEEKLY = 6000
TOKEN_BUDGET_MONTHLY = 8000
TOKEN_BUDGET_YEARLY = 10000
def get_token_budget(batch_type: str) -> int:
return {
"daily": TOKEN_BUDGET_DAILY,
"weekly": TOKEN_BUDGET_WEEKLY,
"monthly": TOKEN_BUDGET_MONTHLY,
"yearly": TOKEN_BUDGET_YEARLY,
}[batch_type]Prompt engineering enforces answer length (80–150 words per answer for daily, more for weekly/monthly). This keeps costs predictable — no runaway 20,000-token responses.
Inter-Batch Sleep
OpenAI enforces rate limits in TPM (tokens per minute) and RPM (requests per minute). Firing 161 requests in a tight loop guarantees 429 errors. I add a fixed 2-second sleep between batches:
for batch_spec in pending_batches:
content = await generate_batch(batch_spec)
repo.upsert_batch(session_id, batch_spec.batch_id, content)
await asyncio.sleep(2.0) # TPM marginThis paces requests well below the tier limit. For a 161-batch job, 2 seconds × 161 = ~5.4 minutes of intentional delay spread across 2–4 hours (most time is spent waiting for GPT-4o responses, not sleeping).
Retry Only Transient Errors
Not all API errors should retry. I use tenacity with a custom retry condition:
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception
def _should_retry_status_error(exception):
if hasattr(exception, "status_code"):
return exception.status_code in [429, 500, 502, 503, 504]
return False
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=60),
retry=retry_if_exception(_should_retry_status_error)
)
async def call_openai_with_retry(prompt: str, max_tokens: int):
response = await openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens
)
return response.choices[0].message.content400-level errors (bad request, invalid JSON) don't retry — they fail fast. 429 and 5xx retry with exponential backoff. This saves cost on permanent failures and avoids retry storms on bad prompts.
Pattern 5: Observable Progress
Users who pay $59.99 and receive an email saying "Your report will arrive in ~180 minutes" need confidence the job is actually running. I use three observability layers:
Structured Logging with Progress
Every batch logs its index, remaining count, and estimated time:
logger.info(
"batch_start",
batch_id=batch_spec.batch_id,
progress=f"{idx + 1}/{len(pending_batches)}",
est_remaining_s=int((len(pending_batches) - idx) * avg_batch_time)
)
# After batch completes
logger.info("batch_complete", batch_id=batch_spec.batch_id, elapsed_s=elapsed)In production (Render logs, or a log aggregator), I can search by session_id and see real-time progress: batch 89/161, est_remaining_s: 4320 (72 minutes).
SSE Status Stream
The frontend success page polls a Server-Sent Events endpoint that reads MongoDB status in real-time:
// Frontend: personal-horoscope/payment/success/page.tsx
const eventSource = new EventSource(
`${API_URL}/api/v1/payments/status/${sessionId}/stream`
);
eventSource.onmessage = (event) => {
const data = JSON.parse(event.data);
if (data.report_status === "READY") {
setStatus("complete");
eventSource.close();
}
};The backend streams updates every 5 seconds:
async def report_status_stream(session_id: str):
async def event_generator():
while True:
report = repo.find_by_session_id(session_id)
yield f"data: {json.dumps({'report_status': report.status})}\n\n"
if report.status in [ReportStatus.READY, ReportStatus.FAILED]:
break
await asyncio.sleep(5)
return StreamingResponse(event_generator(), media_type="text/event-stream")Users see a live updating page: "Generating your horoscope... 45% complete" without refresh.
Backoff Polling as Fallback
For jobs longer than 30 minutes, I add exponential backoff polling to reduce server load:
let pollInterval = 2000; // Start at 2s
const poll = async () => {
const res = await fetch(`/api/v1/payments/status/${sessionId}`);
const data = await res.json();
if (data.report_status === "READY") {
setStatus("complete");
return;
}
// Backoff: 2s → 5s → 15s (cap at 15s for 4-hour jobs)
pollInterval = Math.min(pollInterval * 2.5, 15000);
setTimeout(poll, pollInterval);
};This keeps the UI responsive without hammering the API during long waits.
What I'd Do Differently
Three mistakes I made (and how I'd avoid them next time):
1. PDF Chunking Should Have Been Day One
I initially rendered the entire 1,720-page PDF in one WeasyPrint call. It worked locally (16GB RAM), then OOM-killed workers in production (2GB containers). The fix — chunked rendering with pypdf merge — should have been the default:
CHUNK_SIZE = 10 # pages per chunk
chunks = []
for i in range(0, len(sections), CHUNK_SIZE):
chunk_pdf = render_pdf_chunk(sections[i:i+CHUNK_SIZE])
chunks.append(chunk_pdf)
final_pdf = merge_pdf_chunks(chunks) # pypdf PdfMergerLesson: Design for the production memory limit from the start, not your laptop's specs.
2. Tuning Batch Size Took Too Long
I started with 7 days per batch (52 daily batches total), shipped to production, then noticed answer quality degradation in user feedback. Reducing to 3 days (122 batches) fixed quality but required re-deploying the manifest and invalidating cached reports.
Better approach: Make batch size a config constant and A/B test on a staging environment with real prompts before launch.
3. No Per-Batch Timeout (At First)
A malformed prompt caused GPT-4o to hang for 8 minutes on one batch, blocking the entire pipeline. I added a timeout wrapper:
async def generate_batch_with_timeout(batch_spec: BatchSpec):
try:
return await asyncio.wait_for(
generate_batch(batch_spec),
timeout=180.0 # 3 minutes max per batch
)
except asyncio.TimeoutError:
logger.error("batch_timeout", batch_id=batch_spec.batch_id)
raiseNow a stuck batch fails fast instead of stalling 160 others behind it.
Conclusion
Long-running AI jobs are fundamentally different from typical web requests. You can't rely on HTTP timeouts, synchronous error handling, or "just retry the whole thing" strategies. The five patterns that made Pulse Clarity production-ready:
- Crash-safe batch persistence — upsert after every API call, resume from completed IDs
- Idempotent task design — guard clauses, webhook deduplication, status checks
- Intelligent batching — balance API efficiency with output quality (3 days/batch, not 7 or 1)
- Cost control — token budgets, inter-batch sleep, retry only transient errors
- Observable progress — structured logs, SSE streams, backoff polling
These aren't theoretical patterns — they're battle-tested across thousands of reports ranging from 15 pages (20 seconds) to 1,720 pages (4 hours). If you're building production AI that runs longer than a few minutes, design for crashes from day one. The cost of retrofitting reliability into a live system is far higher than building it in from the start.
The complete system handles concurrent orders across four products (Life Clarity, Personal Blueprint, Personal Horoscope, and a bundle), uses product-specific Celery queues to isolate fast jobs from slow jobs, and has processed real customer payments through Stripe with zero lost orders due to worker crashes.
If your AI job can't survive a container restart halfway through, it's not production-ready. Build crash recovery first, optimize speed second.
Frequently Asked Questions
The most reliable pattern is crash-safe batch persistence: after every GPT-4o API call, upsert the result to MongoDB using a $pull + $push idempotency pattern. Store a unique batch_id for each unit of work. On task retry, check get_completed_batch_ids() and skip already-completed batches. A worker crash at batch 89 of 161 resumes at batch 89 — not batch 1 — with zero wasted API calls or double billing.
Use guard clauses at task entry: check if report.status == ReportStatus.READY before any processing begins. If already complete, return early without calling OpenAI. For webhook deduplication (e.g. Stripe), check status != PENDING before dispatching tasks. Combined with task_acks_late=True and reject_on_worker_lost=True in Celery config, this makes every task safe to retry without double-billing or duplicate delivery emails.
Three days per batch is the practical sweet spot based on production testing. At seven days per batch, GPT-4o output quality degrades — answers become shorter and more generic past day four. At one day per batch, quality is highest but API call counts and costs increase significantly. Production data showed 3-day batches achieved 90% of the quality of 1-day batches at 70% lower API cost.