Why Every AI API Call Needs a Rate Limiter (Even on Day One)
Without rate limiting, a single user can exhaust your entire monthly Gemini or OpenAI budget in minutes — intentionally or not.
See also: Celery + FastAPI production task queue and reducing GPT-4o costs from $203 to $14 per run.
The affiliate marketing SaaS I built has 9 AI-powered tools, each calling Google Gemini 2.5 Flash for text or Gemini 2.5 Flash Image for visuals. Every tool runs through a Next.js Server Action with four gates: auth, rate limit, validate, execute. Without Gate 2, a user clicking "Generate" on a Facebook ad copy tool 30 times in 10 seconds sends 30 API calls. Multiply that across image generation tools — where each call costs more and takes longer — and one enthusiastic user can burn through a week's API budget in an afternoon.
Rate limiting also protects you from accidental abuse. Double-clicks on a loading button, browser refresh during a pending request, and React Strict Mode double-invoking Server Actions in development all create duplicate API calls. A rate limiter with request locking catches these before they hit Gemini.
The good news: a production-quality per-user rate limiter costs $0 to run and takes about 30 minutes to implement. I put all 9 tools behind the same limiter in src/lib/rate-limit.ts. The bad news — which I didn't fully appreciate until I thought about Vercel's architecture — is what happens when that $0 solution meets a second server instance.
The $0 Implementation: Sliding Window in Memory
A per-user sliding window rate limiter needs only a JavaScript Map and timestamps — no external infrastructure, no monthly cost, and roughly 30 minutes to build from scratch.
How a Sliding Window Works
A fixed window limiter resets at clock boundaries — 30 requests per minute means 30 at 12:00:59 and another 30 at 12:01:00. A sliding window tracks individual request timestamps and counts only those within the last 60 seconds. At any moment, the limit reflects actual recent activity, not an arbitrary clock boundary. For AI tools where users generate content in bursts, sliding windows produce fairer behavior.
The Implementation
Each user gets an entry in a Map storing their recent request timestamps and a locked flag for double-click prevention. Before counting, expired timestamps fall outside the window. Image tools use a separate, stricter cooldown because each Gemini Image call is slower and more expensive than a text generation call.
// src/lib/rate-limit.ts
/** Per-user sliding window state stored in memory */
type UserRateState = {
/** Unix ms timestamps of recent requests within the active window */
requests: number[];
/** Prevents duplicate Server Action calls from rapid UI clicks */
locked: boolean;
};
type RateLimitStore = Map<string, UserRateState>;
export type RateLimitResult = {
allowed: boolean;
/** Unix timestamp (ms) when the user can retry — NOT a duration */
retryAfter?: number;
};
type RateLimitOptions = {
limit?: number;
windowMs?: number;
cooldownMs?: number;
};
const store: RateLimitStore = new Map();
const DEFAULT_LIMIT = 30;
const DEFAULT_WINDOW_MS = 60_000;
/** Image tools: minimum gap between consecutive generation calls */
export const IMAGE_COOLDOWN_MS = 5_000;
/**
* Remove timestamps outside the sliding window.
* Called before every count to keep the array bounded.
*/
function cleanExpiredRequests(
requests: number[],
windowMs: number,
now: number
): number[] {
return requests.filter((ts) => now - ts < windowMs);
}
/**
* Check whether a user is within their rate limit.
* Defaults: 30 requests per 60-second sliding window.
*/
export async function checkRateLimit(
userId: string,
options: RateLimitOptions = {}
): Promise<RateLimitResult> {
const limit = options.limit ?? DEFAULT_LIMIT;
const windowMs = options.windowMs ?? DEFAULT_WINDOW_MS;
const cooldownMs = options.cooldownMs ?? 0;
const now = Date.now();
let state = store.get(userId);
if (!state) {
state = { requests: [], locked: false };
store.set(userId, state);
}
// Double-click prevention: reject if a request is already in flight
if (state.locked) {
return { allowed: false, retryAfter: now + 500 };
}
// Image cooldown: enforce minimum gap since last request
if (cooldownMs > 0 && state.requests.length > 0) {
const lastRequest = state.requests[state.requests.length - 1];
const elapsed = now - lastRequest;
if (elapsed < cooldownMs) {
return { allowed: false, retryAfter: lastRequest + cooldownMs };
}
}
state.requests = cleanExpiredRequests(state.requests, windowMs, now);
if (state.requests.length >= limit) {
// Oldest request in window determines when the slot opens
const oldestInWindow = state.requests[0];
return { allowed: false, retryAfter: oldestInWindow + windowMs };
}
// Lock, record, unlock after a short delay
state.locked = true;
state.requests.push(now);
setTimeout(() => {
const current = store.get(userId);
if (current) current.locked = false;
}, 300);
return { allowed: true };
}
/** Stricter limit for image generation tools */
export async function checkImageRateLimit(
userId: string
): Promise<RateLimitResult> {
return checkRateLimit(userId, {
limit: 10,
windowMs: 60_000,
cooldownMs: IMAGE_COOLDOWN_MS,
});
}
Return retryAfter as a Unix timestamp in milliseconds, not a duration in seconds. The client computes Math.ceil((retryAfter - Date.now()) / 1000) on every tick and displays an exact countdown. Duration-based responses drift because network latency and render timing aren't accounted for.
The function returns { allowed: true } on success or { allowed: false, retryAfter: number } when blocked. Every Server Action on the platform calls this before touching Gemini. Total infrastructure cost: $0.
Wiring Rate Limiting Into Every Server Action as Gate 2
Rate limiting belongs at Gate 2 of every Server Action — after auth (no point rate-limiting unauthenticated requests) but before Zod validation and the AI call (fail fast before spending tokens).
The 4-Gate Server Action Pipeline
I documented the full 4-gate pattern in How I Built a Multi-Step AI Wizard With Next.js Server Actions. Every AI tool follows the same sequence. Gate 2 is where rate limiting lives — the same checkRateLimit call in all 9 Server Actions.
// lib/tools/facebook-ad-copy/actions.ts
"use server";
import { auth } from "@/lib/auth";
import { checkRateLimit } from "@/lib/rate-limit";
import { generateAdCopy } from "./service";
import { adCopyInputSchema, type AdCopyOutput } from "./schemas";
type ActionResult<T> =
| { success: true; data: T }
| { success: false; error: string; retryAfter?: number };
export async function generateAdCopyAction(
rawInput: unknown
): Promise<ActionResult<AdCopyOutput>> {
// Gate 1: Auth — reject unauthenticated requests immediately
const session = await auth();
if (!session?.user?.id) {
return { success: false, error: "Unauthorized" };
}
// Gate 2: Rate limit — before validation or AI call
const { allowed, retryAfter } = await checkRateLimit(session.user.id);
if (!allowed) {
return {
success: false,
error: "Rate limit exceeded. Please wait before trying again.",
retryAfter,
};
}
// Gate 3: Zod validation — reject malformed input before Gemini
const parsed = adCopyInputSchema.safeParse(rawInput);
if (!parsed.success) {
return {
success: false,
error: parsed.error.issues[0]?.message ?? "Invalid input",
};
}
// Gate 4: Service call — only runs when all gates pass
try {
const data = await generateAdCopy(parsed.data);
return { success: true, data };
} catch (err) {
const message = err instanceof Error ? err.message : "Generation failed";
return { success: false, error: message };
}
}
Client-Side Countdown Using retryAfter
When Gate 2 returns retryAfter, the UI shows a countdown instead of a generic error. The component reads the timestamp and decrements every second:
// Simplified countdown hook in the tool UI component
const [cooldownSeconds, setCooldownSeconds] = useState(0);
useEffect(() => {
if (cooldownSeconds <= 0) return;
const timer = setInterval(() => {
setCooldownSeconds((prev) => Math.max(0, prev - 1));
}, 1000);
return () => clearInterval(timer);
}, [cooldownSeconds]);
async function handleGenerate(input: AdCopyInput) {
const result = await generateAdCopyAction(input);
if (!result.success && result.retryAfter) {
const secondsLeft = Math.ceil((result.retryAfter - Date.now()) / 1000);
setCooldownSeconds(secondsLeft);
}
}
Never throw from Server Actions — always return structured error objects. A thrown exception becomes an opaque 500 to the client. The retryAfter field on a structured return lets the UI tell the user exactly when to retry instead of showing a generic "something went wrong" message.
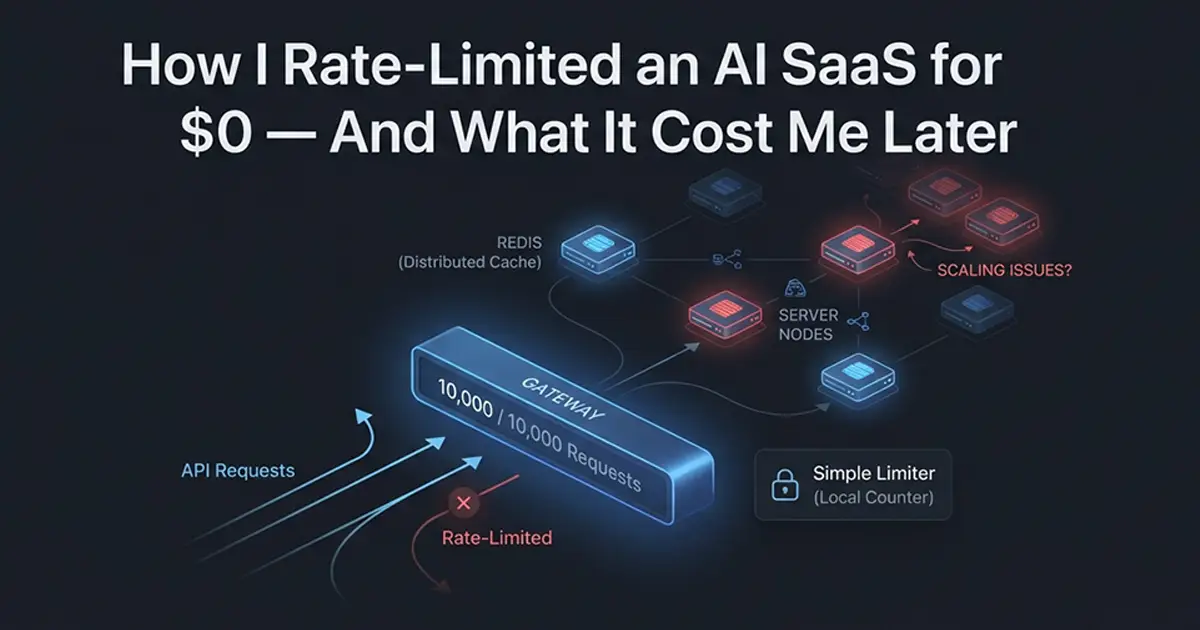
What Breaks When Vercel Spins Up a Second Instance
In-memory rate limiting fails silently at scale — each server instance runs its own counter, and a user hitting two instances simultaneously gets double the allowed requests.
How Vercel Creates Multiple Instances
Vercel runs Next.js as serverless functions. Under normal load, requests land on one warm instance. When traffic spikes, Vercel spins up additional instances to handle concurrent requests. Each instance is an isolated Node.js process with its own memory space — including its own copy of the in-memory Map in rate-limit.ts.
Three Failure Modes
Multi-instance doubling: User A sends 30 requests to instance 1 and hits the limit. Their next request routes to instance 2, which has an empty Map. User A gets another 30 requests. At 30 req/min per instance with 3 active instances, the effective limit becomes 90 req/min — triple what you configured.
Restart wipe: Any redeploy, cold start, or instance recycling destroys the in-memory Map. A user blocked 10 seconds ago can immediately send requests again because the new instance has no memory of prior activity.
Cold start reset: Vercel recycles idle instances frequently. Each recycle is a fresh Map. For a product with bursty usage patterns, users regularly get "free" limit resets without any code change on your end.
This failure is silent — no errors, no logs, no alerts. You only discover it when you check your Gemini quota dashboard or API usage bill and see patterns that don't match your 30 req/min setting. The rate limiter appears to work. Users aren't complaining. Your API costs are climbing anyway.
No money has been lost on the platform yet — it runs on a single Vercel instance in invite-only mode with controlled traffic. The in-memory limiter works correctly in that context. The limitation is documented in code comments as known future work for the next infrastructure milestone.
The Migration to Redis: Same Interface, Different Backing Store
Migrating to Redis-backed rate limiting requires changing only one file — if you designed the interface correctly from the start.
Why Upstash for Vercel Deployments
Traditional Redis uses TCP connections, which are unreliable in Vercel's serverless environment where functions spin up and down constantly. Upstash provides HTTP-based Redis that works natively with serverless and edge functions. The free tier covers 10,000 commands per day — sufficient for a small SaaS. Setup takes 2–3 hours versus the 30 minutes for the in-memory version.
The Interface That Makes Migration Trivial
The function signature should hide the backing store entirely. Server Actions call checkRateLimit(userId) and receive { allowed, retryAfter }. They never know whether the answer came from a Map or Redis.
// src/lib/rate-limit.types.ts
/** Shared contract — callers depend on this, not the implementation */
export type RateLimitResult = {
allowed: boolean;
retryAfter?: number;
};
export type RateLimiter = (userId: string) => Promise<RateLimitResult>;
// ─── v2: Upstash implementation (swap rate-limit.ts, callers unchanged) ───
import { Ratelimit } from "@upstash/ratelimit";
import { Redis } from "@upstash/redis";
const redis = Redis.fromEnv();
const textLimiter = new Ratelimit({
redis,
limiter: Ratelimit.slidingWindow(30, "1 m"),
prefix: "ratelimit:text",
});
const imageLimiter = new Ratelimit({
redis,
limiter: Ratelimit.slidingWindow(10, "1 m"),
prefix: "ratelimit:image",
});
export async function checkRateLimit(
userId: string
): Promise<RateLimitResult> {
const { success, reset } = await textLimiter.limit(userId);
return {
allowed: success,
retryAfter: success ? undefined : reset,
};
}
export async function checkImageRateLimit(
userId: string
): Promise<RateLimitResult> {
const { success, reset } = await imageLimiter.limit(userId);
return {
allowed: success,
retryAfter: success ? undefined : reset,
};
}
Every Server Action that called checkRateLimit in the v1 in-memory implementation calls the same function in v2. Zero changes to the 9 action files — only rate-limit.ts changes. That is the payoff of defining the interface before the implementation.
My mistake was not doing this cleanly from day one. Early versions leaked Map-specific details into calling code before I properly encapsulated the limiter. A clean abstraction makes v1 → v2 a file swap. A leaky one makes it a 1–2 day refactor across all 9 tools.
In-Memory vs Redis: When Each Approach Is Right
In-memory rate limiting is the right call at zero scale — Redis is the right call before you need it, not after you discover the failure mode on a production bill.
| In-Memory (Map) | Redis (Upstash) | |
|---|---|---|
| Cost | $0 forever | $0 free tier (10k cmds/day) |
| Setup time | ~30 minutes | ~2–3 hours |
| Works with multiple instances | ❌ Each instance is isolated | ✅ Shared across all instances |
| Survives server restarts | ❌ Wiped on restart/cold start | ✅ Persistent |
| Latency overhead | ~0ms (in-process) | ~5–20ms (HTTP round-trip) |
| Best for | Single instance, invite-only, early stage | Any multi-instance or production scale |
| Refactor cost when you outgrow it | High (touches all callers if interface leaks) | N/A — already production-grade |
The decision isn't in-memory vs Redis. It's whether you design the interface to make that swap invisible. I got the rate limiter right. I almost got the interface right. The difference cost me nothing today and will cost me a day later.
For products expecting rapid user growth, start with Upstash immediately. The free tier costs nothing and setup is 2–3 hours. The in-memory approach only makes sense if you're certain you'll stay single-instance indefinitely — which, on Vercel, you won't.
I write about these production AI infrastructure patterns on hassanr.com because they're the decisions that separate a demo from a product. Hassan Raza — full-stack and AI engineer — builds SaaS platforms where rate limiting, structured Server Action errors, and infrastructure-agnostic interfaces are decided on day one, not patched on day 90.
Frequently Asked Questions
Place a shared checkRateLimit call at Gate 2 in every Server Action — after auth, before validation and the AI API call. On the affiliate marketing SaaS I built, all 9 AI tools use the same pattern: authenticate the session, call checkRateLimit(userId), return a structured error if denied, then validate input with Zod and call Gemini. The function implements a per-user sliding window (30 requests per minute by default) and returns { allowed, retryAfter } where retryAfter is a Unix timestamp. The client reads retryAfter to display an exact countdown timer. Image generation tools use a separate, stricter cooldown because each call costs more and runs slower than text generation.
In-memory rate limiting stores counters in a local Map per server instance, while Redis shares one counter across all instances. With in-memory limiting at 30 req/min, three Vercel instances running simultaneously give a user up to 90 effective requests per minute — each instance has an independent counter with no shared state. Redis (via Upstash) maintains a single sliding window that every instance reads and writes against. In-memory counters are also wiped on server restart, cold start, or redeploy — a user who hit their limit seconds ago can retry immediately after any restart event. Redis counters persist across all of those events.
Use Upstash when you need shared rate limits across multiple Vercel instances or counters that survive server restarts. Upstash provides HTTP-based Redis that works in Vercel's serverless and edge environments where TCP Redis connections are unreliable. The free tier includes 10,000 commands per day — enough for a small SaaS at early traffic levels. Setup takes roughly 2–3 hours: create a Redis database, add environment variables, swap the implementation in rate-limit.ts while keeping the same checkRateLimit interface. For a single-instance, invite-only product with controlled traffic, an in-memory sliding window remains a valid pragmatic choice — but design the interface so migration to Upstash is a one-file swap.