The Problem with Sync LLM Calls
Pulse Clarity is not a logged-in app with a chat box. Users submit birth data on a Next.js 16 marketing site, pay via Stripe Checkout, and receive a branded PDF by email (with optional download from Vercel Blob). There are no user accounts, JWT, or OAuth — Stripe is the purchase gate.
See also: FastAPI + Celery + Redis production stack and GPT-4o cost reduction from $203 to $14.
My first prototype tried to run the full pipeline inside a FastAPI route: Stripe webhook → natal chart → GPT-4o → WeasyPrint PDF → email. That works for Life Clarity (~15–25 pages, ~15–20 seconds). It breaks completely for Personal Horoscope: 161 sequential GPT-4o batch calls, ~8,600 answers, ~173 PDF chunks, and documented run times of 2–4 hours (up to a 6-hour worker soft limit on Render).
Blocking HTTP on any of that means timeouts, duplicate charges on retry, and burned tokens with nothing delivered. The Personal Horoscope alone would need thousands of naive one-answer-per-call requests — economically and operationally impossible at scale.
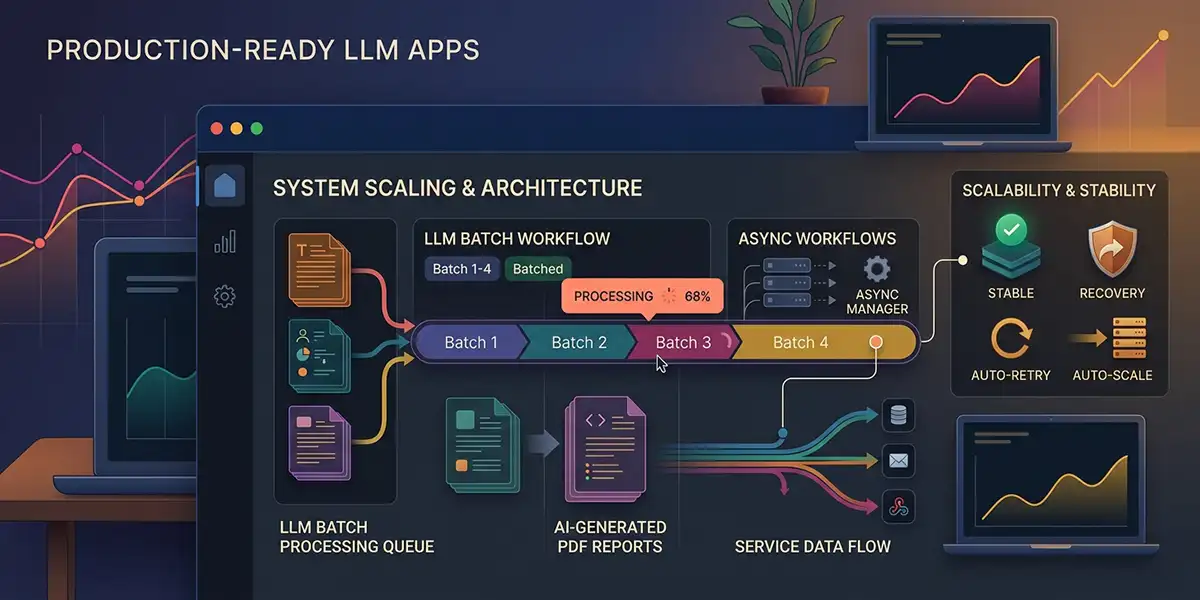
The fundamental rule: Never block an HTTP request on LLM inference. Stripe webhooks should verify payment and enqueue work — then return. Generation belongs in Celery workers with product-specific queues.
The fix is async-first design: immediate confirmation (order email, status polling), background workers for all model calls, and batching strategies tuned per product — not one-size-fits-all.
Product Scale: One Platform, Four Pipelines
One backend monorepo powers four live products. Each has different LLM orchestration, timeouts, and worker isolation:
| Product | Output scale | Gen time (documented) | LLM pattern |
|---|---|---|---|
| Life Clarity Report | ~15–25 pages | ~15–20s | 4 parallel OpenAI Agents (Identity, Emotional, Career, Growth) |
| Personal Life Blueprint | ~33 pages, 52 AI sections | ~2–3 min | 52 batched calls (BATCH_SIZE=5, 1.5s inter-batch sleep) |
| Personal Horoscope | ~1,720 pages, 8,600 answers | ~2–4 hr | 161 sequential time-period batch calls (2.0s inter-batch sleep) |
| Bundle (all 3) | Combined delivery | ~2–4 hr | Coordinator dispatches 3 queue-isolated sub-tasks |
Primary model in production: gpt-4o (hardcoded across products; gpt-4o-mini noted for local testing). There is no RAG, no embeddings, no vector DB — context comes from deterministic pre-computation (Kerykeion charts, 365-day transits, numerology) injected into prompts.
Architecture: Async-First Design
Production deployment on Render runs 5 Docker services from render.yaml: 1 FastAPI web API + 4 Celery workers (clarity, blueprint, horoscope, bundle). Local dev uses docker-compose.yml with Redis + API + workers.
┌──────────────────┐ ┌─────────────┐ ┌─────────────────────────────┐
│ Next.js 16 FE │ │ Stripe │ │ FastAPI (app/api/v1/) │
│ Checkout + poll │────▶│ Webhook │────▶│ Verify → enqueue Celery │
│ SSE stream │ │ HMAC sig │ │ Return 200 (idempotent) │
└──────────────────┘ └─────────────┘ └─────────────────────────────┘
│ │
│ GET /payments/status/{session_id} ▼
│ GET .../stream (SSE) ┌──────────────────┐
│ │ Redis 7 │
│ │ Celery broker │
│ │ + 24h chart cache│
│ └────────┬─────────┘
│ │
│ ┌────────────────────────────────────┼────────────────────┐
│ ▼ ▼ ▼ ▼
│ queue.life_clarity queue.personal_ queue.personal_ queue.bundle
│ blueprint horoscope
│ │ │ │ │
│ └────────────────────┴─────────────────┴────────────────────┘
│ │
│ 4-stage pipeline per product:
│ 1. Pre-computation (Kerykeion, transits)
│ 2. AI content (GPT-4o / Agents SDK)
│ 3. PDF (WeasyPrint chunks → pypdf merge)
│ 4. Vercel Blob upload + SendGrid email
│ │
└──────────────────────────────┴── MongoDB (payments, reports,
upsert_section / upsert_batch)Key architectural decisions:
- Thin routes, thick services: FastAPI v1 router → service layer → repositories (
BaseRepository). Not microservices — one monorepo with queue-separated workers. - Stripe webhook idempotency:
payment_service.pyignores dispatch ifreport_status != PENDING— duplicate webhooks don't double-bill or double-generate. - MongoDB for crash-safe state: Per-product report docs with
upsert_section/upsert_batchafter each API call; resume viaget_completed_*_ids. - Redis dual role: Celery broker/result backend + SHA-256 chart cache (86400s TTL) in
app/services/computation/cache.py. - No blocking on PDF size:
render_pdf()rejects >30 sections — horoscope forces chunked path (CHUNK_SIZE=10→ ~173 chunks).
Async isn't about making GPT faster — it's about decoupling checkout from a job that can run for four hours while the customer gets immediate confirmation and live status updates.
Three LLM Orchestration Patterns
Pulse Clarity uses three distinct orchestration models — not one generic "call OpenAI" helper:
1. Parallel multi-agent (Life Clarity)
OpenAI Agents SDK: four domain agents created in life_clarity/agents.py, executed via run_agents() in app/services/ai/runner.py with asyncio.gather(..., return_exceptions=True). Structured output via Pydantic SectionsOutput. Four parallel calls → merged ReportSection list → ~15–20s end-to-end.
# app/services/ai/runner.py — simplified
async def run_agents(agents: list, user_prompt: str) -> list[ReportSection]:
results = await asyncio.gather(
*[Runner.run(agent, user_prompt) for agent in agents],
return_exceptions=True,
)
sections = []
for result in results:
if isinstance(result, Exception):
raise result # or handle partial failure policy
sections.extend(result.final_output.sections)
return sections2. Batched sequential sections (Personal Blueprint)
generate_all_sections() in personal_blueprint/runner.py: 52 sections from a SectionSpec manifest, BATCH_SIZE = 5, INTER_BATCH_SLEEP = 1.5 for TPM headroom. Each section persisted via on_section_complete → repo.upsert_section().
3. Time-period batch pipeline (Personal Horoscope)
Fundamentally different from Blueprint's one-section-per-call model: one API call generates multiple calendar periods × 20 Q&A answers. build_batch_manifest() in manifest.py defines 161 batches (122 daily + 26 weekly + 12 monthly + 1 yearly). Daily batches reduced to 3 days per call for GPT-4o word-count quality. INTER_BATCH_SLEEP = 2.0.
Intelligent Batch Processing
The biggest throughput win for Horoscope wasn't "more workers" — it was batching calendar periods into single completions instead of 8,600 individual calls.
| Approach | API calls (Horoscope) | Feasibility |
|---|---|---|
| One call per answer | ~8,600 | Rate limits, cost, days of runtime |
| Time-period batches (production) | 161 | ~2–4 hr with sleeps + retries |
| Life Clarity (parallel agents) | 4 | ~15–20s |
| Blueprint (5 sections per batch) | 52 | ~2–3 min |
# personal_horoscope/runner.py — batch loop pattern
INTER_BATCH_SLEEP = 2.0
async def generate_all_batches(
session_id: str,
manifest: list[BatchSpec],
on_batch_complete: Callable,
) -> None:
completed_ids = repo.get_completed_batch_ids(session_id)
for spec in manifest:
if spec.batch_id in completed_ids:
continue # crash-safe resume
prompt = build_daily_batch_prompt(ctx, spec) # transit-aware
raw = await call_gpt4o_json(prompt, budget=TOKEN_BUDGET_DAILY)
parsed = json.loads(raw) # retry on parse failure
repo.upsert_batch(session_id, spec.batch_id, parsed)
on_batch_complete(spec.batch_id, len(manifest))
await asyncio.sleep(INTER_BATCH_SLEEP) # TPM marginPro tip: Horoscope batches are tuned to GPT-4o output limits (80–150 words per answer in prompts), not just input token ceilings. Quality constraints drove reducing daily batches to 3 days per call.
Pre-Computation Before the LLM
Every product runs run_precomputation() in orchestrator.py before any model call. The LLM never invokes astrology libraries — it receives a ComputationContext built deterministically:
- Natal chart: Kerykeion
get_chart(), cached in Redis (SHA-256 key from birth data, 86400s TTL) - Blueprint only: numerology (
get_numerology_profile()), lucky colours - Horoscope:
get_horoscope_data()— 365-day Moon sign, phase, aspects per day via Kerykeion;_extract_daily_transits()threads date-specific data into each batch prompt
If pre-computation fails (ComputationError), generation stops — no partial context sent to GPT. This is compute-before-LLM, not RAG retrieval.
# Universal 4-stage pipeline (all products)
async def run_report_pipeline(session_id: str, birth_data: BirthData):
ctx = await run_precomputation(birth_data) # libraries first
if ctx.error:
raise ComputationError(ctx.error)
sections = await generate_ai_content(ctx) # GPT-4o only sees ctx
pdf_bytes = await render_pdf_chunked(sections) # CHUNK_SIZE=10
blob_url = await upload_pdf(pdf_bytes) # Vercel Blob
await send_report_email(session_id, blob_url) # SendGridProduct-Specific Celery Queues
One shared queue would let a 4-hour horoscope job starve 20-second Life Clarity reports. Pulse Clarity defines named queues in app/workers/queues.py:
# app/workers/queues.py
QUEUE_LIFE_CLARITY = "queue.life_clarity"
QUEUE_PERSONAL_BLUEPRINT = "queue.personal_blueprint"
QUEUE_PERSONAL_HOROSCOPE = "queue.personal_horoscope"
QUEUE_BUNDLE = "queue.bundle"
# app/workers/tasks.py — routing examples
@app.task(queue=QUEUE_LIFE_CLARITY)
def generate_report(session_id: str): ...
@app.task(queue=QUEUE_PERSONAL_HOROSCOPE, soft_time_limit=360 * 60)
def generate_personal_horoscope_task(session_id: str): ...
@app.task(queue=QUEUE_BUNDLE)
def generate_bundle_task(session_id: str):
# Dispatches 3 sub-tasks; tracks lc_status / bp_status / ph_status
# Sends combined email when last completes (_on_bundle_sub_report_ready)| Queue | Worker config (Render) | Why isolated |
|---|---|---|
queue.life_clarity |
concurrency=2 | Fast turnaround (~15–20s) |
queue.personal_blueprint |
dedicated worker | ~2–3 min, 52 batched calls |
queue.personal_horoscope |
concurrency=1, ≥2GB RAM | 2–4 hr, scale horizontally not vertically |
queue.bundle |
coordinator only | Orchestrates 3 product queues without blocking one another |
Warning: Engineering rules target hundreds of concurrent report requests across products. Mixing horoscope and clarity on one worker pool breaks SLAs for the $19.99 instant-feel product.
Celery Worker Fleet on Render
Reliability settings applied across workers:
task_acks_late=True— don't ack until task completestask_reject_on_worker_lost=True— requeue if worker dies mid-horoscopeworker_prefetch_multiplier=1— one task at a time per worker (critical for long jobs)- Idempotency: skip if
ReportStatus.READYalready set
# render.yaml — 5 services (simplified)
# 1. Web: Dockerfile.api (FastAPI + Uvicorn)
# 2–5. Workers: Dockerfile.worker.clarity | blueprint | horoscope | bundle
celery -A app.workers worker \
--queues=queue.personal_horoscope \
--concurrency=1 \
--loglevel=infoHoroscope worker uses soft_time_limit=360 minutes (6 hours) based on observed ~190 minute runs. Bundle worker dispatches sub-tasks with is_bundle=True and coordinates combined delivery.
Robust Error Handling
LLM APIs hit 429s and 5xxs. Pulse Clarity uses tenacity with exponential backoff — retry only on _should_retry_status_error (429 + 5xx) in all runners. JSON parse failures in horoscope trigger retry on malformed model output.
Crash-safe checkpointing
# After every batch/section API call — not at end of job
def on_batch_complete(session_id: str, batch_id: str, payload: dict):
repo.upsert_batch(session_id, batch_id, payload)
# MongoDB $pull + $push idempotency in personal_horoscope_repo.py
# On worker restart
completed = repo.get_completed_batch_ids(session_id)
for spec in manifest:
if spec.batch_id in completed:
continue # resume without re-billing customer
await generate_batch(spec)Webhook and task failure policy
- Stripe webhook routes return 200 even on downstream errors (
payments.py) — Stripe won't infinite-retry; failures logged and surfaced via report status - Stage failures → Celery retry →
ReportStatus.FAILEDon max retries - Global exception handlers in
app/core/exceptions.py
Monitoring & Observability
No Segment or GA4 in the frontend — operational visibility is structlog with JSON logs in production (app/core/logging.py). Every task binds session_id and report_type at start.
logger.info(
"batch.progress",
session_id=session_id,
batch_id=batch_id,
completed=len(completed_ids),
total=len(manifest),
est_remaining_s=estimate_remaining(manifest, completed_ids),
)
logger.info(
"task.completed",
session_id=session_id,
generation_time_s=elapsed,
report_type="personal_horoscope",
)Fields worth tracking in production:
batch.progress— horoscope ETA for support and debugginggeneration_time_s— per product, per deploypdf.merged— chunk merge success (~173 chunks for horoscope)task.completed/ failure reasons by queue- OpenAI token usage per session (cost control)
scripts/check_env.py validates OpenAI, Stripe, SendGrid, Vercel Blob, MongoDB, and Redis before deploy. E2E smoke tests: test_full_pipeline.py, test_blueprint_pipeline.py, test_horoscope_pipeline.py (no Stripe required).
Cost & Rate Control
Async batching enables margin on one-time purchases ($19.99 – $99.99 bundle):
| Technique | Where | Impact |
|---|---|---|
| Redis chart cache (24h TTL) | computation/cache.py |
Avoid recomputing Kerykeion for retries/resumes |
| Inter-batch sleep | 1.5s Blueprint, 2.0s Horoscope | TPM / rate-limit margin |
| Per-batch token ceilings | TOKEN_BUDGET_* in manifest, token_budget.py |
Prevent runaway completion length |
| Time-period batching | Horoscope manifest | ~8,600 calls → 161 calls |
| Pre-computation (no RAG) | All products | Smaller, deterministic prompts; no embedding infra |
| Chunked PDF | CHUNK_SIZE=10 |
Memory-safe render on 2GB horoscope workers |
# Per-product token budgets — horoscope/manifest.py
TOKEN_BUDGET_DAILY = ...
TOKEN_BUDGET_WEEKLY = ...
TOKEN_BUDGET_MONTHLY = ...
TOKEN_BUDGET_YEARLY = ...
def get_token_budget(product: str, section: str) -> int:
# life_clarity / personal_blueprint use token_budget.py
...Frontend Status: SSE & Backoff Polling
The Next.js 16 frontend (React 19, Tailwind 4) never waits on generation. After Stripe Checkout:
- Immediate: order confirmation email; horoscope estimates 180 minutes in
payment_service.py - Status polling:
GET /api/v1/payments/status/{session_id} - SSE:
report_status_stream()inapp/services/sse.py→GET .../streamfor real-time updates - Horoscope success page: backoff polling 2s → 5s → 15s (
personal-horoscope/payment/success/page.tsx)
Secrets stay server-side — frontend only exposes NEXT_PUBLIC_API_URL and support email. CORS from explicit CORS_ORIGINS (wildcard banned in prod per engineering standards).
Lessons Learned
Building multi-product LLM PDF generation taught me patterns that transfer to any high-volume inference app:
1. Async from day one — even for the "fast" product
Life Clarity could fake sync for a while. Horoscope cannot. One Celery enqueue pattern for all products keeps Stripe webhooks simple and prevents a second refactor.
2. Batch by semantic unit, not arbitrary count
Horoscope batches calendar periods; Blueprint batches 5 sections; Life Clarity parallelizes domains. The unit of batching should match how GPT maintains coherence.
3. One queue per latency class
15-second and 4-hour jobs must not share workers. Product-specific queues on Render were cheaper than debugging starvation in production.
4. Pre-compute everything libraries can do
365-day transits before 161 LLM calls means every daily answer can reference unique Moon/aspect data without the model doing math — and without a vector database.
5. Checkpoint after every paid API call
upsert_batch / upsert_section after each call, not at job end. A crash at batch 140 of 161 must not restart from batch 1.
6. Match UX to job duration
Instant confirmation email + honest ETA (180 min for horoscope) + SSE/polling beats a spinner that times out at 30 seconds.
The best LLM architecture makes checkout feel instant while a four-hour pipeline runs invisibly — and survives worker restarts without charging the customer twice.
Conclusion
Production LLM apps are about decoupling purchase from inference. Pulse Clarity runs FastAPI + Celery + Redis + MongoDB on Render, with four product-specific queues, three orchestration patterns, deterministic pre-computation, and chunked WeasyPrint PDFs uploaded to Vercel Blob.
From 4 parallel agent calls to 161 horoscope batches producing 8,600 answers — the patterns differ, but the foundation is the same: enqueue early, batch intelligently, checkpoint often, and never block HTTP on GPT-4o.
If you're building a consumer AI product with variable job length, scaffold queues and pre-computation before you tune prompts. The model is easy to swap; the workflow around it is what keeps unit economics viable at $19.99–$99.99 one-time price points.
Frequently Asked Questions
HTTP requests have hard timeout limits, typically 30–60 seconds. LLM jobs that run for minutes or hours will time out, leaving the client without a response. Worse, if the client or webhook system retries (e.g. Stripe sending duplicate events), you get duplicate processing — double charges, double emails, and wasted API costs. The correct pattern is to return 200 immediately from the webhook handler, enqueue the work to a Celery queue, and let users poll for status via SSE or backoff polling.
Use product-specific Celery queues — one queue per latency class. A shared queue lets a 4-hour horoscope job starve 20-second Life Clarity reports, breaking SLAs for instant-feel products. With separate named queues (queue.life_clarity, queue.personal_horoscope), each gets its own dedicated worker with appropriate concurrency and memory settings. Horoscope workers run at concurrency=1 with 2GB RAM; Life Clarity workers run at concurrency=2 for fast parallel throughput.
Parallel agents run multiple independent LLM calls simultaneously using asyncio.gather() — ideal for fast, domain-separated tasks like the four-agent Life Clarity report (Identity, Emotional, Career, Growth agents run in parallel and finish in 15–20 seconds total). Sequential batching processes related items in ordered groups — ideal for calendar-based content like the horoscope product where 161 batches must maintain consistent narrative context across 365 days of personalized answers. Choose based on whether your outputs are independent or share context.