Why Webhooks (Not Polling) for Payment-Triggered AI Jobs
Webhooks deliver payment confirmation immediately; polling wastes resources checking for status changes that may not happen for seconds, minutes, or hours — and it cannot trigger a Celery task without a polling loop. One paid order triggers 161 GPT-4o calls over 141 minutes, delivers 1,725 pages (~14 MB), and costs about $14 after optimization (down from $203).
See also: long-running async AI job pipelines.
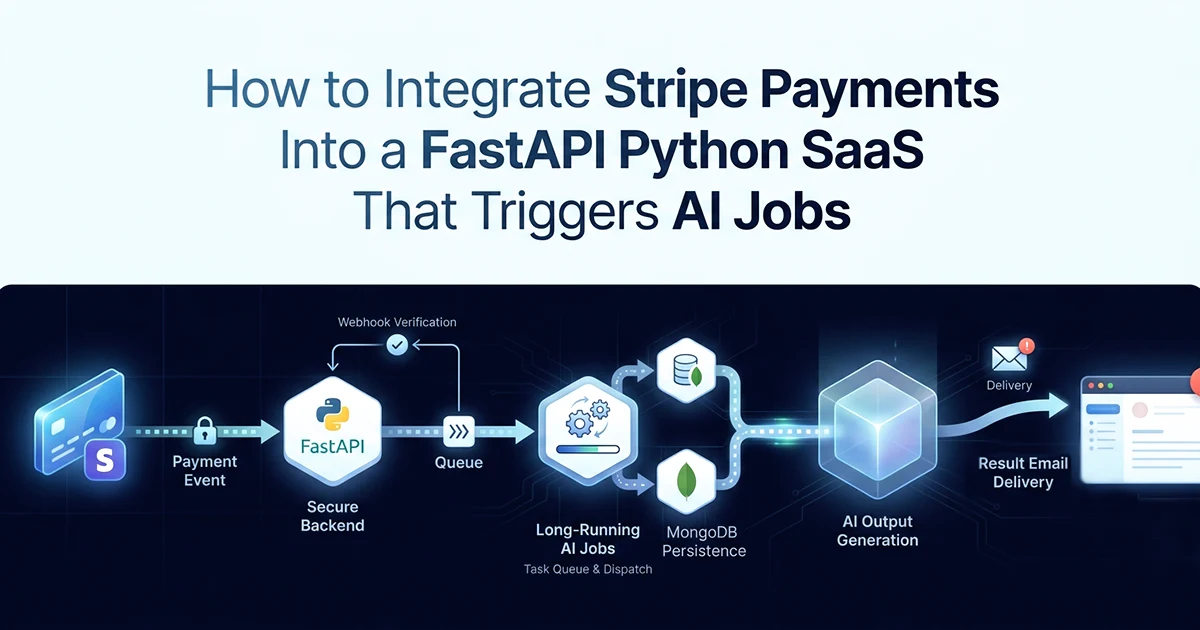
I built an AI report generation SaaS where a single Stripe payment triggers between four parallel GPT-4o calls and 161 sequential calls, producing a PDF delivered by email hours later. Polling Stripe's API from the frontend every five seconds cannot hold a connection for four hours. A webhook fires once when checkout.session.completed arrives; Celery handles the rest on dedicated worker queues.
The alternative — polling GET /v1/checkout/sessions/{id} from a background thread until status is complete — works for simple SaaS with instant fulfillment. It fails when fulfillment takes two to four hours and requires dispatching a Celery task with customer metadata. You would need a cron job or polling loop checking Stripe every N seconds, then correlating session IDs to pending orders in MongoDB. Webhooks push the event to you the moment payment completes; your handler runs once and exits.
The end-to-end flow: customer selects report type → POST /api/v1/payments/checkout creates a Stripe Checkout Session → customer pays on Stripe-hosted page → webhook fires → signature verified → idempotency check → status updated → Celery task dispatched → AI pipeline runs → PDF uploads to Vercel Blob → delivery email sent → status becomes ready.
| Mistake | What breaks | Fix |
|---|---|---|
await request.json() before verification |
Signature check fails — bytes transformed | await request.body() first, always |
| Return 500 on downstream error | Stripe retries → potential duplicate dispatch | Always return 200; log internally |
| Dispatch task before status update | Race condition: retry sees status=pending → dispatches again | Update DB status → then dispatch |
| No idempotency check | Duplicate jobs on Stripe retries or admin re-runs | Check status == pending before processing |
| Use payment_intent.succeeded | Webhook fires before checkout metadata is attached | Use checkout.session.completed instead |
| Store price IDs in code | Hard to update prices without deploy | Store in env variables per product |
Why checkout.session.completed, not payment_intent.succeeded
payment_intent.succeeded fires when payment is authorized — before the Stripe Checkout Session metadata (customer birth date, coordinates, report type) is fully attached. checkout.session.completed fires after the full checkout flow and includes all metadata your AI pipeline needs. For any job that needs checkout metadata, checkout.session.completed is the right event. I also handle checkout.session.expired (mark status expired, no job) and payment_intent.payment_failed (mark status failed). All three are listed in HANDLED_EVENTS; only checkout.session.completed dispatches Celery work.
The webhook_timestamp detail matters for long jobs: I inject session["created"] — the Stripe session creation Unix timestamp — into the Celery task metadata. The AI pipeline anchors "Day 1" of a 365-day report to the purchase timestamp, not the processing timestamp. Without it, a four-hour delay between payment and worker start would shift every date reference by half a day.
The Checkout Session: Embedding the Data Your AI Pipeline Needs
All customer data needed by the AI pipeline — names, dates, locations — should be embedded in the Stripe Checkout Session metadata at creation time, so it arrives with the webhook payload without a second database lookup.
Metadata fields in my production checkout: first_name, birth_date, birth_place, latitude, longitude, report_type, timezone, and optional birth_time. These travel with the Stripe session and return in the webhook payload under session["metadata"]. The Celery task receives them as a dict argument — no second database lookup to reconstruct customer input. MongoDB stores the same metadata at checkout creation for idempotency and admin tools, but the webhook handler can build the task payload entirely from the Stripe session object.
What metadata to store in the session
# app/api/routes/payments.py
import structlog
import stripe
from fastapi import APIRouter
from app.core.config import settings
from app.repositories.payment_repo import payment_repo
from app.schemas.payment import CheckoutRequest
logger = structlog.get_logger()
router = APIRouter()
PRICE_MAP = {
"life_clarity": settings.LIFE_CLARITY_STRIPE_PRICE_ID,
"personal_blueprint": settings.PERSONAL_BLUEPRINT_STRIPE_PRICE_ID,
"personal_horoscope": settings.PERSONAL_HOROSCOPE_STRIPE_PRICE_ID,
"bundle": settings.BUNDLE_STRIPE_PRICE_ID,
}
@router.post("/checkout")
async def create_checkout_session(request: CheckoutRequest):
# Store ALL AI pipeline data in Stripe metadata — arrives with webhook
metadata = {
"first_name": request.first_name,
"birth_date": request.birth_date.isoformat(),
"birth_place": request.birth_place,
"latitude": str(request.latitude),
"longitude": str(request.longitude),
"report_type": request.report_type,
"timezone": request.timezone,
}
if request.birth_time:
metadata["birth_time"] = request.birth_time.isoformat()
session = stripe.checkout.Session.create(
mode="payment",
line_items=[{"price": PRICE_MAP[request.report_type], "quantity": 1}],
success_url=f"{settings.FRONTEND_URL}/success?session_id={{CHECKOUT_SESSION_ID}}",
cancel_url=f"{settings.FRONTEND_URL}/cancel",
metadata=metadata,
customer_email=request.email,
)
await payment_repo.create({
"stripe_session_id": session.id,
"report_type": request.report_type,
"metadata": metadata,
"status": "pending",
"report_status": "pending",
})
logger.info("checkout_created", session_id=session.id, report_type=request.report_type)
return {"checkout_url": session.url}
The price ID resolver pattern
One env variable per product — LIFE_CLARITY_STRIPE_PRICE_ID, PERSONAL_BLUEPRINT_STRIPE_PRICE_ID, PERSONAL_HOROSCOPE_STRIPE_PRICE_ID, BUNDLE_STRIPE_PRICE_ID — mapped through a dict lookup instead of a long if/elif chain. Update prices in Stripe dashboard and env vars without touching routing logic.
On checkout creation I also insert a payment record into MongoDB with stripe_session_id, report_type, full metadata, and both status and report_status set to pending. This record exists before the customer completes payment — when the webhook arrives, the handler loads by session ID and finds the pre-created document. No race where the webhook fires before checkout creation finishes, because the record is written synchronously before returning the checkout URL to the frontend.
Stripe metadata values must be strings. Convert all non-string values — dates, floats, booleans — at checkout creation. The webhook returns the exact same strings; type conversion happens in the handler when building the Celery task argument, not at storage time.
Signature Verification: The Step That Breaks Most FastAPI Integrations
Stripe's HMAC signature is computed on the raw request bytes — calling await request.json() before verification transforms the bytes and causes SignatureVerificationError even when the secret is correct. This Stripe webhook FastAPI Python tutorial production pattern starts with raw bytes, every time.
I hit this on day one: the webhook route used a Pydantic model dependency that parsed JSON before my handler ran. Signature verification failed on every request despite copying the secret correctly from the dashboard. Switching to await request.body() and passing raw bytes to stripe.Webhook.construct_event() fixed it in one line. Most Stack Overflow answers show request.json() — that pattern works for unsigned endpoints, not Stripe webhooks. Test with the Stripe CLI before deploying to production.
Why request.body() must be called exactly once, before anything else
# app/api/routes/stripe_webhook.py
import structlog
import stripe
from fastapi import APIRouter, HTTPException, Request
from app.core.config import settings
from app.services.payment_service import HANDLED_EVENTS, handle_event
logger = structlog.get_logger()
router = APIRouter()
@router.post("/webhook")
async def stripe_webhook(request: Request):
# CRITICAL: read raw bytes FIRST — Stripe signature is computed on raw bytes
payload = await request.body()
sig_header = request.headers.get("stripe-signature")
if not sig_header:
raise HTTPException(status_code=400, detail="Missing stripe-signature header")
try:
event = stripe.Webhook.construct_event(
payload, # raw bytes — NOT json.loads(payload)
sig_header,
settings.STRIPE_WEBHOOK_SECRET,
)
except stripe.error.SignatureVerificationError as e:
logger.warning("stripe_signature_failed", error=str(e))
raise HTTPException(status_code=400, detail="Invalid signature")
except ValueError:
raise HTTPException(status_code=400, detail="Invalid payload")
# Always return 200 — Stripe retries non-200 for up to 3 days
if event["type"] in HANDLED_EVENTS:
try:
await handle_event(event)
except Exception as e:
logger.error("webhook_handler_error", event_type=event["type"], error=str(e))
# Log and continue — DO NOT re-raise
return {"received": True} # always HTTP 200
Testing webhook verification locally
Run stripe listen --forward-to localhost:8000/api/v1/payments/webhook. The CLI signs webhooks with a test secret — set STRIPE_WEBHOOK_SECRET to the CLI's signing secret during development, not the dashboard secret. Production uses the webhook endpoint secret from the Stripe dashboard. I wrap verification in construct_webhook_event() in app/integrations/stripe/client.py so the route handler stays thin and testable.
The stripe-signature header carries the HMAC Stripe computed on the exact bytes you received. FastAPI middleware or dependency injection that reads the body before your route handler runs will break verification — ensure nothing consumes request.body() before your webhook route. If you need logging, log after construct_event succeeds, not before.
Always return HTTP 200 {"received": True} regardless of downstream errors. If MongoDB is down, if Celery is unavailable, if validation fails — still return 200. Stripe retries any non-200 response for up to 3 days. A 500 during a DB hiccup means Stripe fires the webhook again after recovery. Errors are logged internally; Celery handles AI retry logic. Stripe's retry mechanism is a last resort, not a primary error handler.
The Idempotency Guard and the Correct Dispatch Order
Check database status before dispatching — and update the database to generating before dispatching the Celery task, not after. Getting this order wrong causes duplicate jobs when Stripe retries the webhook.
Why Stripe retries happen and how to handle them
Stripe retries webhook delivery up to 3 days on any non-200 response or delivery timeout. If your database was briefly unavailable during the first delivery but the Celery task was already dispatched, MongoDB still shows report_status=pending → idempotency check passes on retry → second Celery task dispatched → customer's order processed twice. The fix: update status to generating first. If that update succeeds, status is no longer pending → idempotency check catches any retry.
The idempotency guard also handles admin re-run tools and accidental double-clicks on internal dispatch buttons. Any code path that could trigger generation checks report_status != pending and skips. Combined with Celery's task_acks_late=True, a worker crash re-queues the task without creating a duplicate webhook dispatch — the status is already generating, so a Stripe retry cannot fire a second job.
The complete dispatch handler
# app/services/payment_service.py
import structlog
from app.models.report_status import ReportStatus
from app.repositories.payment_repo import payment_repo
from app.workers.tasks import (
generate_report,
generate_blueprint_task,
generate_horoscope_task,
generate_bundle_task,
)
from app.integrations.email import send_order_confirmation_email, send_bundle_confirmation_email
logger = structlog.get_logger()
HANDLED_EVENTS = {
"checkout.session.completed",
"checkout.session.expired",
"payment_intent.payment_failed",
}
TASK_MAP = {
"life_clarity": (generate_report, "queue.life_clarity"),
"personal_blueprint": (generate_blueprint_task, "queue.personal_blueprint"),
"personal_horoscope": (generate_horoscope_task, "queue.personal_horoscope"),
"bundle": (generate_bundle_task, "queue.bundle"),
}
async def _handle_checkout_completed(session: dict):
session_id = session["id"]
payment = await payment_repo.find_by_session_id(session_id)
if not payment:
logger.error("payment_not_found", session_id=session_id)
return
# IDEMPOTENCY GUARD: only process if status is still pending
if payment["report_status"] != ReportStatus.PENDING:
logger.info("duplicate_webhook_skipped", session_id=session_id,
current_status=payment["report_status"])
return
metadata = {
**session["metadata"],
"customer_email": session.get("customer_details", {}).get("email"),
"stripe_payment_intent": session.get("payment_intent"),
"webhook_timestamp": session["created"], # purchase time, not processing time
"amount": session.get("amount_total", 0),
}
# UPDATE STATUS FIRST — before dispatching task (prevents race condition)
await payment_repo.update_one(
{"stripe_session_id": session_id},
{"$set": {
"report_status": ReportStatus.GENERATING,
"customer_email": metadata["customer_email"],
}},
)
report_type = session["metadata"]["report_type"]
if report_type == "personal_horoscope":
await send_order_confirmation_email(
metadata["customer_email"],
estimated_minutes=180,
)
elif report_type == "bundle":
await send_bundle_confirmation_email(metadata["customer_email"])
task_fn, queue_name = TASK_MAP[report_type]
task_fn.apply_async(args=[session_id, metadata], queue=queue_name)
logger.info("job_dispatched", session_id=session_id, report_type=report_type, queue=queue_name)
Never dispatch a Celery task before updating the database status. If apply_async succeeds but the status update fails, and Stripe retries the webhook, your idempotency check still sees status=pending and dispatches a second time. The status update is the lock. Update MongoDB to generating → then dispatch. Product routing uses a TASK_MAP dict — life_clarity to queue.life_clarity, personal_horoscope to queue.personal_horoscope — so adding a fifth product means one dict entry, not another branch in a 40-line if/elif chain.
Long-Job UX: Send the Confirmation Email Before Starting the 4-Hour Task
For AI jobs that take hours, send the order confirmation email immediately after the webhook fires — before dispatching the Celery task — so the customer gets immediate closure and knows what to expect.
The UX problem with long-running paid tasks
If a customer pays and gets nothing for four hours, they assume something broke and open a dispute. Send the confirmation email in the webhook handler — not from the Celery task. The webhook handler is the only place where you know for certain: payment succeeded, customer email is verified, and the job is about to start. The Celery worker might not start for minutes if the queue is busy; the webhook fires within seconds of payment.
SendGrid templates in my stack are inline HTML strings, not dynamic SendGrid templates. The confirmation email is simple: order number, product name, estimated delivery window. The delivery email — sent hours later from the Celery worker — attaches the PDF as base64 (within SendGrid's 30 MB limit) plus a Vercel Blob download link as backup. Two emails, two moments, two different jobs.
What the confirmation email should say
Not just "order confirmed" — include the specific estimated delivery time. "Your report is being generated. You'll receive it by email in approximately 2–4 hours." For the horoscope product I use estimated_minutes=180. Bundle customers get a separate bundle confirmation before three sub-tasks dispatch to their respective queues. Fast reports (~15–20 seconds) skip the confirmation email — the delivery email arrives before the customer checks their inbox. Long jobs need the intermediate signal; short jobs do not.
The webhook is the last moment you know everything: payment confirmed, customer email verified, job about to start. For long-running AI tasks, this is the exact moment to set expectations — not from the Celery task, not from a polling endpoint, but here.
Order Status Tracking: Polling, SSE, and What to Store in MongoDB
Store all order state in MongoDB keyed by stripe_session_id — the same key Stripe provides in every webhook — so any event can look up and update the same document without a secondary ID system.
The MongoDB payment document lifecycle
Status lifecycle: pending → generating → ready | failed. Frontend polling: GET /api/v1/payments/status/{session_id} returns current report_status. SSE endpoint: GET /api/v1/payments/status/{session_id}/stream for live updates. Bundle orders track lc_status, bp_status, ph_status plus per-product pdf_url fields. Honest current state: no customer-facing progress endpoint exists for individual jobs — only bundle tracking via SSE. Individual report customers are notified by the final delivery email only.
Using stripe_session_id as the MongoDB primary lookup key means every Stripe event — completed, expired, failed — updates the same document without inventing a secondary order ID. The success page passes session_id from the URL query param; polling uses the same key the webhook handler uses. One identifier end to end.
When to use SSE vs polling
SSE suits live progress on long jobs where the customer watches a progress page — bundle orders with three parallel pipelines benefit most. Polling is simpler for shorter jobs or when the customer just wants to know when delivery is ready. Hassan Raza documents the Celery worker architecture that runs after dispatch on hassanr.com — including queue-per-product routing and section-level crash recovery in the FastAPI + Celery production guide. This post covers everything before the first GPT-4o call starts: checkout metadata, signature verification, idempotency, and dispatch order.
Frequently Asked Questions
Create a POST route, read raw bytes with await request.body(), verify the signature, and always return HTTP 200. Hassan Raza built a production Stripe webhook FastAPI Python tutorial pipeline that never calls request.json() before verification — JSON parsing transforms bytes and breaks Stripe's HMAC check. Use stripe.Webhook.construct_event(payload, sig_header, STRIPE_WEBHOOK_SECRET) on the raw body. Handle checkout.session.completed for payment fulfillment. Load the order from MongoDB, check report_status is pending before processing, update status to generating, then dispatch Celery via apply_async(). Log downstream errors internally; Stripe retries non-200 responses for up to 3 days.
Inside checkout.session.completed, update database status to generating, then dispatch Celery with apply_async(). Hassan Raza never dispatches before the status update — dispatch first risks duplicate jobs when Stripe retries. Route products to dedicated queues: queue.life_clarity, queue.personal_blueprint, queue.personal_horoscope, queue.bundle. Inject webhook_timestamp from session created so the AI pipeline anchors Day 1 to purchase time, not processing time. For long-running tasks taking 2–4 hours, send a confirmation email before dispatching the Celery task so customers get immediate closure.
Call stripe.Webhook.construct_event on raw request bytes, not parsed JSON. In FastAPI, use await request.body() once before any JSON parsing — never await request.json() first. Pass the stripe-signature header and STRIPE_WEBHOOK_SECRET from the Stripe dashboard in production, or from stripe listen CLI during local testing. SignatureVerificationError means wrong secret or transformed body. stripe listen --forward-to localhost:8000/api/v1/payments/webhook signs events with a test secret — use that in development, not the dashboard secret.